今天是我们 App 发版的日子,产品小姐姐突然跟我说,百度应用市场登录不上去了。我打开她发的链接 http://app.baidu.com ,在 Chrome 上输入账号密码登录,完成后却还是未登录的模样。
没事,反正百度那也没几个下载量,下次再说!
咦,不对,上次好像就说了同样的话…
好吧,那该仔细思索一下了。偶尔挂还好说,谁没几个 Bug,可是这都一个多月了啊?
我看着浏览器陷入了沉思,然后我灵光一现把链接换成了 https,然后就正常了!
跟三三吐槽了一下百度这 Bug,他告诉了我一个有趣的现象:在 FireFox 上其实是正常的,这个 Bug 是因为 Chrome 没有遵守标准。
这样那问题就有趣起来了,看来并不是一个简单的疏忽。因此我决定把整个问题复盘一下,看看这背后究竟是怎么回事。
现象描述
在 Chrome 上,打开 http://app.baidu.com 进行登录,完成后 http 页面并没有登录状态,和未登录一样。而此时直接访问 https://app.baidu.com 却会发现已经登录了。
在 FireFox 上,打开 http://app.baidu.com 进行登录,之后无论是 http 还是 https 页面皆是正常。
而且重启大法,重装大法都不好使。
定位问题
本文属于科普向的,因此会有一些基础概念的介绍,会用引用表示,熟悉者可跳过。
既然区别在 Http 和 Https 上,那首先简要说明一下它们是什么:
Http
Http 是超文本传输协议,可以简单理解成访问网页用的协议。类似的协议还有 FTP、SSL 等。
Https
Https 简单说就是加密的 Http。
Http 是明文的,不够安全,还可能被篡改。在早期很多网上冲浪的用户会发现某些本没有广告的网站会出现广告,或者网站下 Apk 结果下下来是另一个 Apk。这些都是因为传输协议用的是 Http,可以被运营商或者路由器篡改,这种现象就叫运营商劫持。而 Https 可以避免这些问题。
还需要简单了解的一下是 Cookies:
Cookies
HTTP 协议是无状态的,意味着在原始情况下,你连续两次访问同一个网站,网站是不知道这两次访问是同一个人的。这会带来什么样的问题呢?会导致用户没法在不同的页面做连续的事情,比如我在淘宝的商品页选好商品下单,跳到付款页面下单,纯从 HTTP 协议的角度来说,网站在付款页面是不知道你商品页面选了啥的,也不知道你是谁。
当然,这种情况并没有发生,聪明的你肯定也想到了,我们可以在每次访问新的页面时把需要的数据传给它,就可以把两个网页连接起来了。有关这部分的具体知识,很推荐一篇文章 有关 Session 的那些事儿。再具体一些的内容因为不是本文重点就不展开了。
简而言之,就是当你登录后,网站会为了辨认你是谁,将你的身份信息用一串字母表示,返回给浏览器,浏览器在之后每次访问这个网站时都会把这串字母附带上,这样网站就能辨认出你了。
Cookies 就是一个浏览器用来存”网站让浏览器帮忙存的数据”的地方。
结合上面的知识,在 Chrome 上,我们通过 http 进行登录,之后 https 能正常显示说明登录状态(也就是 Cookies)是正常的,而在 http 页面没有登录,说明很可能是 Cookies 出了问题。
在 Chrome 的控制台,我们可以很轻松看到网站具体存了哪些 Cookies。
我们先查看 http://app.baidu.com 的 Cookies 信息,如下图。之前提到过 Cookies 里的内容是网站用来鉴别用户身份的,因此如果泄露别人就可能可以直接登录你账号了,所以需要打码。
之所以说”可能”,是因为网站检测到这次请求不符合常用电脑、常用地点时,可以增加额外的二次验证(都是隐私啊=。=)

再查看 http://app.baidu.com 的 Cookies 信息。
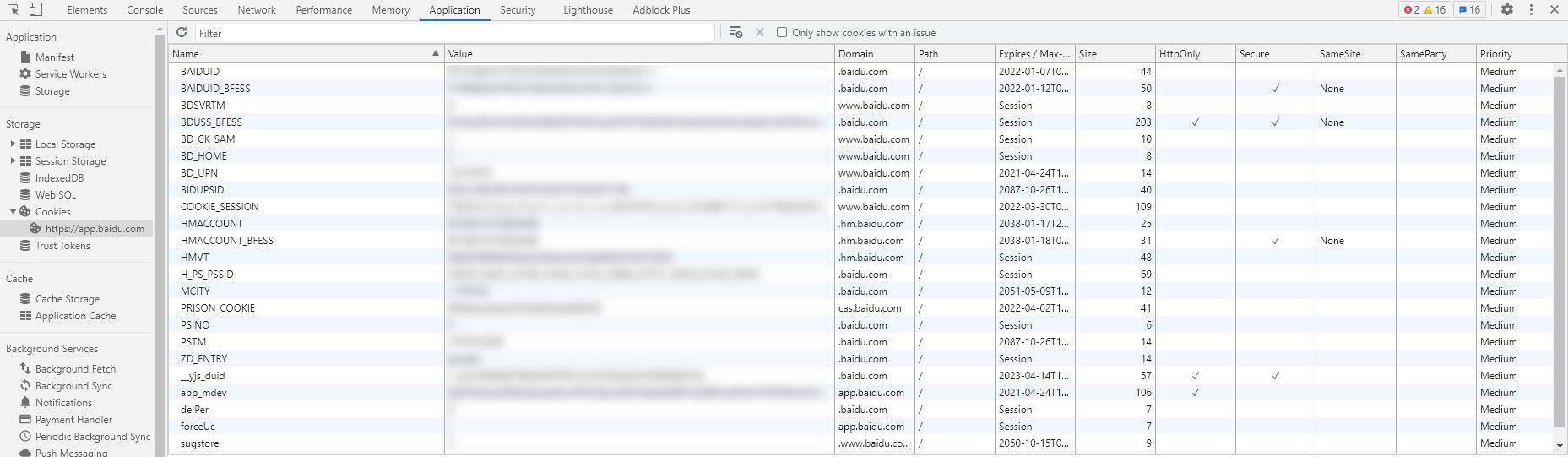
经过对比我们可以发现,https 的 Cookies 里比 http 多了 BAIDUID_BFESS、_yjs_duid、BDUSS_BFESS这三个 Key。
在这里我们需要更详细地了解一下 Cookies 的机制:
Cookies 的传输
对于一次网络请求,可以分成两部分看待:请求(Request)与响应(Response)。
请求就是用户把自己想要浏览的内容和需要的数据发给服务器,比如登录可以是请求 http://example/login?username=admin&password=123456 。访问网站的登录页(example/login),并携带用户输入的要登录的账号(admin)密码(123456)。当然实际的登录不会这样简单,这有一些安全问题。
响应就是服务器接受到了你的请求,把它决定返回的内容发给你。
再具体到请求/响应的格式,它们都由三部分构成:起始行/状态行、请求头/响应头(Headers)、正文(Body)。
起始行/状态行可以先不管。Headers 是用来传递一些用户不需要看见的内容,比如约定的格式,用的什么浏览器,和一些约定的数据。Body 则是用户实际可见的内容,比如用户上传一张图片,Body 就是图片本身,用户浏览一个网页,Body 就是肉眼可见的那些内容。
那么创建 Cookies,就是网站在响应的 Headers 里添加一个
Set-Cookie字段,这样浏览器之后每次对该网站请求都会携带这些信息给网站。比如这个响应就可以是:
HTTP/1.0 200 OK Content-type: text/html Set-Cookie: yummy_cookie=choco Set-Cookie: tasty_cookie=strawberry [页面内容]而我们之后再访问该网站,请求就可以是:
GET /sample_page.html HTTP/1.1 Host: www.example.org Cookie: yummy_cookie=choco; tasty_cookie=strawberry
而 Cookies 除了基本的要传递的内容,还能更精准地控制内容的生效访问。比如失效时间、可以在哪些网站共享等等。
Cookies 的参数
比如一个复杂一点的 Cookie 是这样的:
Set-Cookie
STOKEN=61d02***96; expires=Sat, 24-Apr-2021 04:00:27 GMT; path=/; domain=passport.baidu.com; secure; httponly可以简单分为两部分,一部分是具体的内容,一部分是附带选项。
比如它要求浏览器保存一个参数名为
STOKEN,内容是61d02***96的 Cookies。然后它的附带选项是:1、expires意思是过期时间是 2021 年 4 月 21 日;2、secure是开启仅 https 发送;3、httponly是开启仅服务器可获取。附带选项有这么几种:Expires、Max-Age、Secure、HttpOnly、Path、SameSite。
详细的不一一展开,具体可参考:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Cookies
重点介绍
Secure:标记为 Secure 的 Cookie 只应通过被 HTTPS 协议加密过的请求发送给服务端。
再观察上面百度的 Cookies,发现 BDUSS_BFESS 含有 Secure 属性,因此可以猜测:这个包含用户身份信息的 Cookie 在 http 的情况下没有携带,在 https 的情况下正常携带,因此在 Chrome 下出现 http://app.baidu.com 无法登录,而 https://app.baidu.com 正常的情况。
那么,为什么 FireFox 会正常呢?
我们先观察一下 FireFox 登录后的 Cookies 信息:(http 和 https 两种情况下内容一致)

可以发现:
1、FireFox 下 Cookies 条目少了很多;(原因我们暂不知道)
2、包含用户身份信息的 Cookie 条目为 BDUSS;(为何和 Chrome 不为同一个原因未知)
3、BDUSS的 Secure 属性没有被设置。
因此,为啥会产生 FireFox 正常,Chrome 不正常的现象的技术原理我们知道了。现在的问题变成了为什么会发生包含身份信息的 Cookie 在 Chrome 下是 Secure 的,在 FireFox 下不是 Secure 的。
根据前文的三三大佬的说法,按照 HTTP 标准,Https 的 Cookies 如果没有携带 Secure 字段,那么是可以和 Http 共享的。而 Chrome 觉得这样不安全,把它们分开了。
基于这种设想,我猜测是不是 Chrome 是把服务器传来的 Cookies 在客户端存储时强行加上了 Secure 字段,从而实现了这个功能。
猜想1:Chrome 把服务器传递的 Cookies 自行加了 Secure 字段
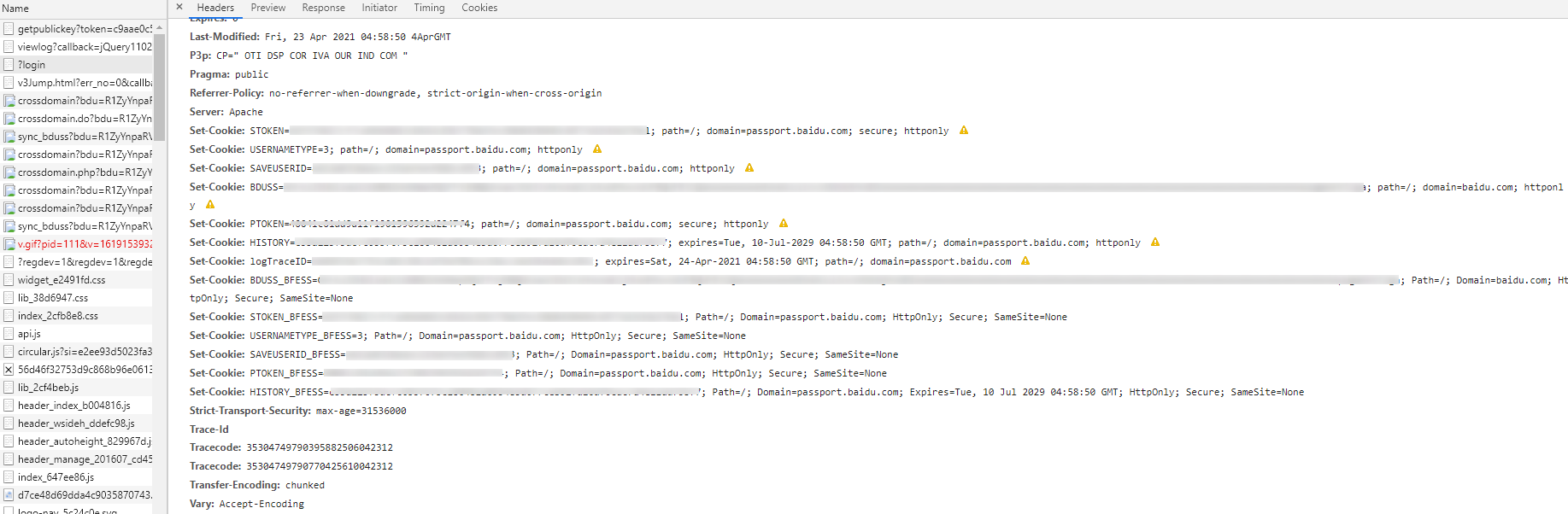
要验证这个猜想,需要查看服务器返回的原始的 Set-Cookie 字段。依旧通过 F12 开发者工具查看:
Chrome 的:
FireFox 的:
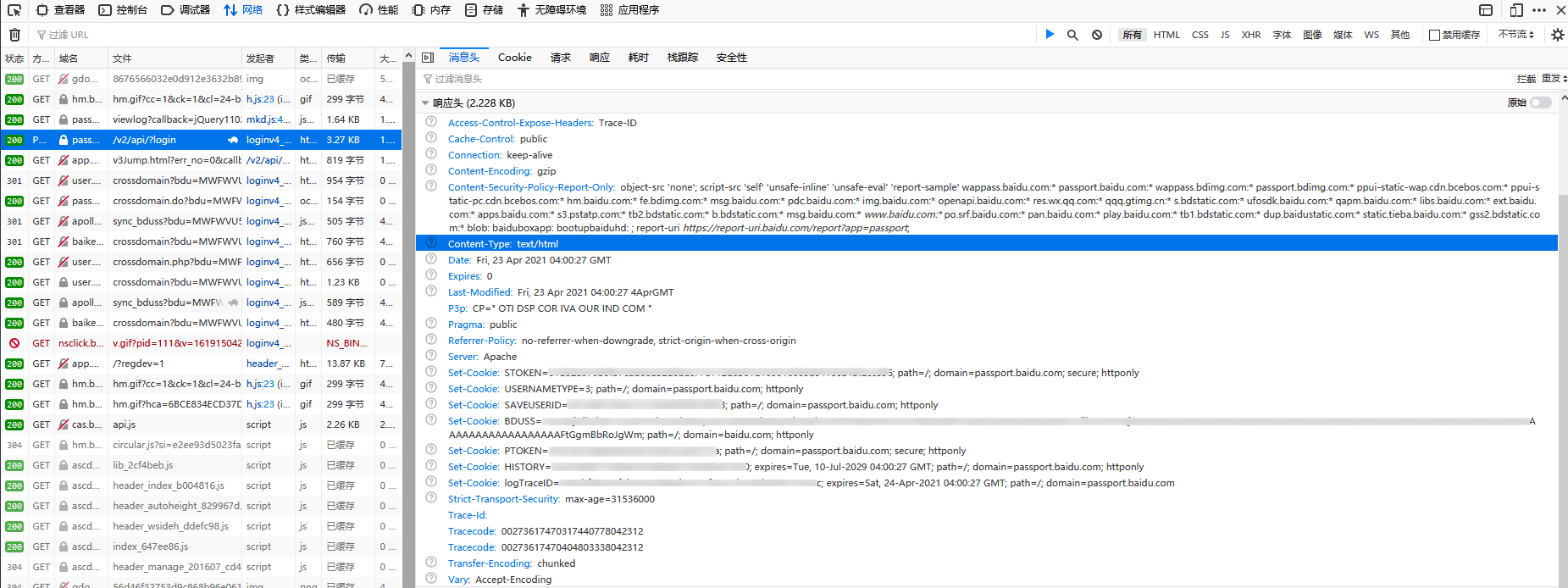
我们可以发现,Chrome 的原始 BDUSS_BFESS 的确有 Secure,因此猜想1基本可以认定是错的。
但是,我们同时也发现了,Chrome 的响应里也出现了 BDUSS,值跟 BDUSS_BFESS 是一样的,而它是没有 Secure,这点与 FireFox 一致。
因此我们衍生出来猜想2:百度对于所有的浏览器都是以 BDUSS为存储用户身份的字段。但是在 Chrome 下这样做失败了,因此用额外的逻辑即 BDUSS_BFESS 进行补救,但是此方式没有 http 场景。
猜想2:百度存储的 BDUSS 字段的 Cookies 在 Chrome 下因为某些原因失败了导致 http 状态无法登录
我在测试过程中,惊奇地发现自己的笔记本并没有复现这个情况。

在 http 状态下,BDUSS 被正确地保存了下来,也因此没有出现 http 页面没法登录的现象。
我第一想法是浏览器拓展导致的,但是两台电脑的 Chrome 配置都是同步的。再检查浏览器版本,问题版是 90,正常版是 85。对 85 进行更新,然后惊喜地发现果然不行了。
再仔细观察 Chrome 的内容,以及切换到 Cookies 页面查看,发现有一部分”异常”数据:
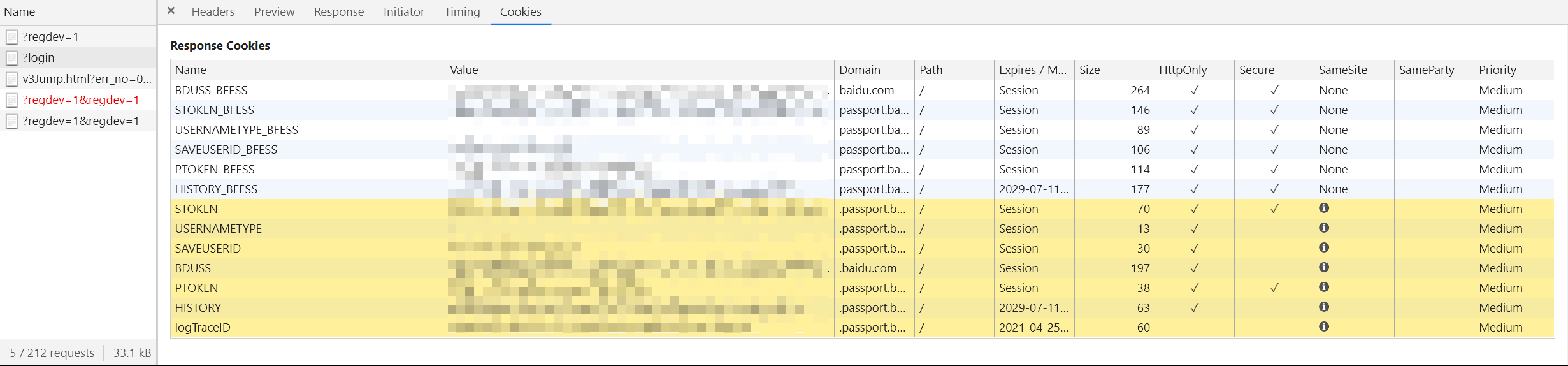
感叹号提示内容:
This Set-Cookie didn’t specifty a “SameSite” atribute, was defaulted to “SameSite=Lax”, and was blocked because it came from a cross-site response which was not the response to a top-level navigation. This response is considered cross-site because the URL has a different scheme than the current site.
好吧,这里提到了 SameSite,之前介绍 Cookies 参数时只介绍了 Secure,看来还是需要介绍一下 SameSite,不过在此之前我们需要简要说明一下 CSRF:
CSRF
全名 Cross-site request forgery,即”跨站请求伪造”。
首先,我们知道每次访问网站,本质上就是携带一些参数去请求一个链接。那我们假设给某条微博点赞的链接是 https://weibo.com/aj/v6/like/add?id=123456,那当用户按下点赞按钮时,会访问如上所述的链接,给 ID 为 123456 的微博点赞,根据我们之前的知识,这次请求自然会携带 Cookies,这样服务器就知道是你点赞了。
那什么是 CSRF 呢?顾名思义,跨站请求伪造,就是用户不知道的情况下(对应:伪造)在 A 站访问了 B 站的内容(对应:跨站请求)。再具体一点,比如我这篇文章里,我骗你点上面那个链接,当你恰好登录了微博的时候就自动给这条微博点赞了。
当然,你肯定会觉得这样有点低端,还需要诱骗用户点击。当然也有直接访问的办法了,比如我上传一张图片,而图片的链接我用了上述链接,这样当你访问这个网站时,会自动加载图片,自然也就访问上述链接了。
这就是一个简单的 CSRF 例子。现实中想实现类似的攻击会比这复杂一些。在多年以前经常会有微博用户发现在自己不知情的情况下转发点赞了一堆广告微博,虽然背后的原因我不清楚,但可能也是类似 CSRF 的手段。
SameSite
SameSite 是一个较新的字段,加入它的原因就是为了解决上面的 CSRF 问题。它的作用是:服务器可以设定 Cookie 在跨站请求时会不会发送。
它有三种值:None、Strict、Lax。
None:浏览器会在相同站点请求、跨站请求时都依旧发送 Cookies。
Strict:浏览器只会在相同站点请求时发送 Cookies。
Lax:浏览器会在相同站点请求时发送 Cookies,但是在一部分跨站请求会发送 Cookies。这部分特殊的请求方式为链接、GET 表单、预渲染。
三种值的用户意义是:
None 会像以前一样,依旧有 CSRF 风险;
Strict 能完全避免 CSRF,但是会显著降低用户体验,比如我在知乎看到了个带货回答点开了淘宝链接,本来我已经登录过了淘宝,但是因为禁止跨站传递 Cookies,我还得重新登录;
Lax 是 Strict 的温和版,它允许了一些情况可以跨站传递 Cookies,避免了上述知乎打开淘宝需要重登录的问题。
因此,我们再去理解上面 Chrome 提示的内容,它说这个网站返回的这条 Cookie 没有指定 SameSite,因此 Chrome 把它默认设置为了 SameSite=Lax。并且被阻止了,因为它是一个跨站响应。而为什么认定是跨站响应呢,因为这两个 URL 有不同的 scheme。
Scheme
我们给链接分组(区分是不是同一个网站之类的)的规则是:
<scheme>://<host><path>
Scheme 的值可以是:http、https、file、ftp、app、*。
我们知道,Chrome 会把它魔改的地方都加个开关放到 flags 页面里。因此我们打开 chrome://flags,搜索 SameSite,内容如下:
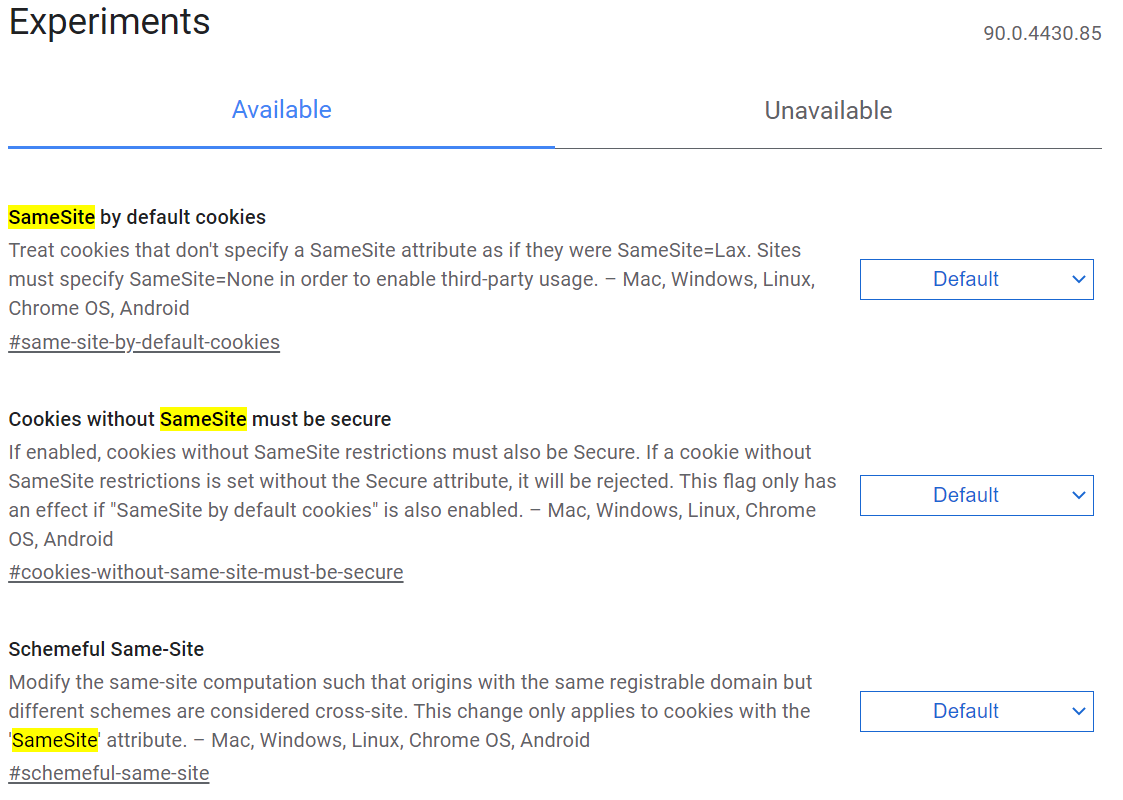
阅读它的说明,你就会明白这件事是个什么情况了。
「SameSite by default cookies」:默认开启 SameSite=Lax,这个修改是在 Chrome 85 上进行的:Feature: Cookies default to SameSite=Lax。实际上在 80 也改过一次但是又改回来了,具体原因就不展开了。
「Cookies without SameSite must be secure」:你的 Cookies 在没有设置 SameSite 时,如果没有 Secure 属性就会被拒绝。
「Schemeful Same-Site」:在 SameSite 的是否相同站点计算时,不同的 schemes 也被认定为不同站点。也就是 http://app.baidu.com 与 https://app.baidu.com 不被认为是相同的站点。
因此,我们把「Schemeful Same-Site」设为 Disabled,就会发现,之前不正常的 http 可以正常登录了。
总结
这个现象的原因就是,Chrome 在新版强行给没有设置 SameSite的 Cookie 设置了,并且对同站的判断没有遵循标准,而是认定 http 和 https 不同站。以至于 http://app.baidu.com 没法登录。
=。=因为我不是 Web 前端,所以对相应技术敏感性有些欠缺,不然可以更快定位。但如果我们是百度的 Web 前端开发,那该怎么解决这个问题呢?有下面几种方案:
1、全站执行 http 自动跳转 https。百度首页 http://baidu.com 就是这样做的,而 http://app.baidu.com 还没跟进。
2、http 下不跳转到 https 执行登录。这样 http 和 https 就是两套 Cookies 了,不会出现之前的 http 没法登录,但是直接切 https 发现已经登录了的情况。但问题在于 http 是明文的,用户的账号密码有一定风险。
3、对包含鉴权信息的那条 Cookie,添加 SameSite=None。这样的问题是依旧面临 CSRF 的风险。
4、让用户换 FireFox。